Arbre DOM et accès à des contenus de la page
Définition :
DOM est l'abréviation de Document Object Model. Le DOM est une interface de programmation normalisée par le W3C, qui permet à des scripts d'examiner et de modifier le contenu du navigateur web. Par le DOM, la composition d'un document HTML ou XML est représentée sous forme d'un jeu d'objets – lesquels peuvent représenter une fenêtre, une phrase ou un style, par exemple – reliés selon une structure en arbre. À l'aide du DOM, un script peut modifier le document présent dans le navigateur en ajoutant ou en supprimant des nœuds de l'arbre.
Exemple :
On associe un arbre DOM au code HTML d'une page .html (ou plus généralement au code XML).
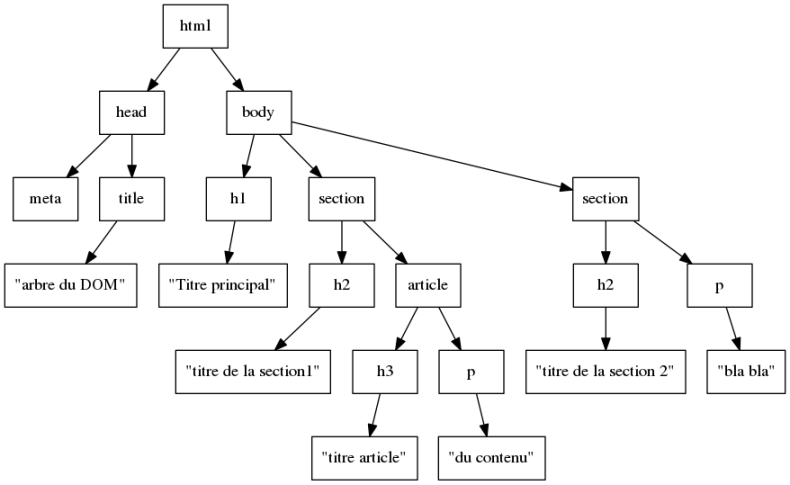
Prenons l'exemple de la page ci-dessous :
<html lang="fr">
<head>
<meta charset="utf-8">
<title> arbre du DOM </title>
</head>
<body>
<h1> Titre principal </h1>
<section>
<h2> titre de la section 1 </h2>
<article>
<h3> titre article </h3>
<p> du contenu </p>
</article>
</section>
<section>
<h2> titre de la section 2 </h2>
<p> bla bla </p>
</section>
</body>
</html>
L'arbre associé à cette page est le suivant :
Définition : Définition d'un arbre
On associe à cette arborescence le vocabulaire usuel sur les arborescences (au programme de Terminale NSI) :
le nœud <html> est le nœud racine
le nœud <html> a deux fils : les nœuds <head> et <body>
les nœuds sans descendants sont les feuilles
...
Des interfaces pour accéder aux éléments de la page
JavaScript représente les éléments de la page avec la structure de l'arbre DOM ci-dessus.
La racine de l'arbre est l'élément document. Ses feuilles sont contenus dans la liste référencée par l'attribut document.children, et chaque élément de cette liste a lui même un attribut .children donnant accès à ses branches.
Méthode : Trouver des objets par classe, id, balise
La méthode document.getElementById permet de sélectionner un élément de l'arbre DOM dont on a défini l'attribut id dans le code html. Si dans une page, le paragraphe que vous êtes en train de lire a été défini par la balise <p id="paragraphe_exemple">. Son id sera donc paragraphe_exemple.
Ainsi, le code suivant permet de le référencer par la variable para ce paragraphe et de lire ou écrire certaines de ses propriétés.
/* Sélectionner l'élément */para = document.getElementById('paragraphe_exemple');
/* Ajouter du texte */para.innerHTML += "texte supplémentaire";
/* Changer la couleur de fond */para.style.backgroundColor = 'red';
La méthode document.getElementsByTagName permet de sélectionner des éléments par balise HTML. On peut le faire sur toute la page, ou seulement pour les enfants d'un élément donné.
/* Sélectionner tous les éléments définis par la balise <h2> du document */titres_niv_2 = document.getElementsByTagName('h2');
/* Changer le texte du second de ces éléments (le titre de cette partie) */titres_niv_2[1].innerHTML = "Nouveau titre";
/* Sélectionner le paragraphe exemple */para = document.getElementById('paragraphe_exemple');
/* Sélectionner tous les éléments définis par la balise <code> du paragraphe exemple */codes_paragraphe = para.getElementsByTagName('code');
/* Changer la couleur de fond du premier de ces éléments. */codes_paragraphe[0].style.background="green";
On peut aussi utiliser document.getElementByClassName() qui permet de sélectionner une classe. Plus d'infos ici : https://developer.mozilla.org/fr/docs/Web/API/Document/getElementsByClassName
Complément : Sélectionner un élément via les sélecteurs Selector
Les 3 méthodes précédentes sont performantes mais limitées. Avec des pages ou applications complexes, elles se révèlent peu souples car nécessitent de faire appel à des boucles, diverses opérations algorithmiques et des filtres sur les résultats obtenus pour pouvoir obtenir une liste d'éléments.
On rappelle donc les 3 fonctions :
getElementById(): recherche un élément d'après son identifiant (attribut id),
getElementsByTagName(): recherche des éléments d'après leur type (balise),
getElementsByClassName(): recherche des éléments d'après leur classe (attribut class)
On a donc introduit 2 nouvelles fonctions, dont la syntaxe permet de faire appel aux sélecteurs CSS. On applique en général ces deux méthodes à partir de la racine document.
querySelector(): retourne le premier élément trouvé satisfaisant au sélecteur (type de retour : Element), ou null si aucun objet correspondant n'est trouvé.
querySelectorAll(): retourne tous les éléments satisfaisant au sélecteur, dans l'ordre dans lequel ils apparaissent dans l'arbre du document (type de retour :NodeList), ou un tableauNodeListvide si rien n'est trouvé.
Exemple : Exemple pour un tableau HTML
On définit un tableau HTML <table id="matable"> avec à l'intérieur des cellules <td>. Je vais pouvoir utiliser ces 2 dernières méthodes assez facilement :
Sélectionner le tableau :
let tableau = document.querySelector('#matable');
Ou sélectionner l'ensemble des cellules <td> du tableau :
let cellules = document.querySelectorAll('#matable td');