Généralités sur les processus

Définition : Qu'est-ce qu'un processus ?
Nous avons vu précédemment que le processeur exécute des instructions en langage machine de manière séquentielle (il exécute les instructions les unes après les autres).
On sait aussi qu'un fichier exécutable (par exemple, les fichiers ayant l'extension .exe sous système d'exploitation Windows) est une séquence d'instructions en langage machine (assembleur).
Sur les systèmes informatiques modernes (ordinateurs, serveurs, téléphones, tablettes, ...) plusieurs programmes peuvent fonctionner « en même temps » :
Navigateurs web,
Explorateur de fichiers,
Lecteur multimédia,
etc.
Si on veut être précis, les programmes ne fonctionnent pas « en même temps » mais plutôt « chacun leur tour » ainsi le processeur exécute quelques instructions d'un programme, puis quelques instructions d'un autre programme, etc.
On appelle chaque programme en cours d'exécution un processus.
Le système d'exploitation (Windows, Linux, MacOS) est en charge de la gestion de ces processus.
États d'un processus
Pour gérer ce « chacun son tour », les systèmes d'exploitation attribuent des « états » au processus.
Voici les différents états :
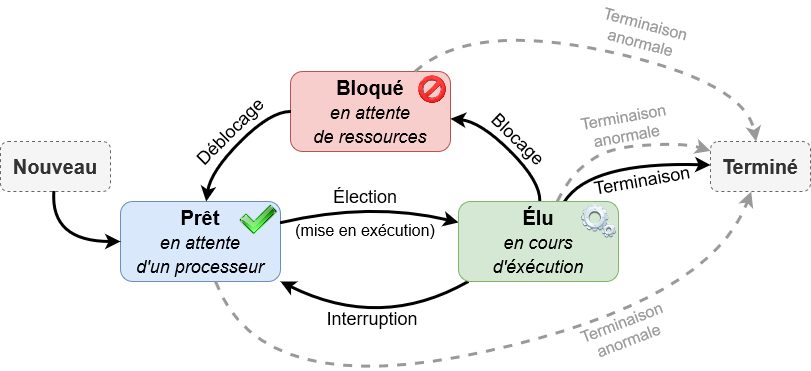
Lorsqu'un processus est en train de s'exécuter (qu'il utilise le microprocesseur), on dit que le processus est dans l'état « élu ».
Un processus qui se trouve dans l'état élu peut demander à accéder à une ressource pas forcément disponible instantanément (par exemple lire une donnée sur le disque dur). Le processus ne peut pas poursuivre son exécution tant qu'il n'a pas obtenu cette ressource. En attendant de recevoir cette ressource, il passe de l'état « élu » à l'état « bloqué ».
Lorsque le processus finit par obtenir la ressource attendue, celui-ci peut potentiellement reprendre son exécution. Mais comme nous l'avons vu ci-dessus, les systèmes d'exploitation permettent de gérer plusieurs processus « en même temps », mais un seul processus peut se trouver dans un état « élu » (le microprocesseur ne peut « s'occuper » que d'un seul processus à la fois). Quand un processus passe d'un état « élu » à un état « bloqué », un autre processus peut alors « prendre sa place » et passer dans l'état « élu ». Le processus qui vient de recevoir la ressource attendue ne va donc pas forcément pouvoir reprendre son exécution tout de suite, car pendant qu'il était dans un état « bloqué » un autre processus a « pris sa place ». Un processus qui quitte l'état bloqué ne repasse pas forcément à l'état « élu », il peut, en attendant que « la place se libère » passer dans l'état « prêt » (sous entendu « j'ai obtenu ce que j'attendais, je suis prêt à reprendre mon exécution dès que la place sera libérée »).
Le passage de l'état « prêt » vers l'état « élu » constitue l'opération « d'élection ». Le passage de l'état élu vers l'état bloqué est l'opération de « blocage ». Un processus est toujours créé dans l'état « prêt ». Pour se terminer, un processus doit obligatoirement se trouver dans l'état « élu ».
On peut résumer tout cela avec le schéma suivant :
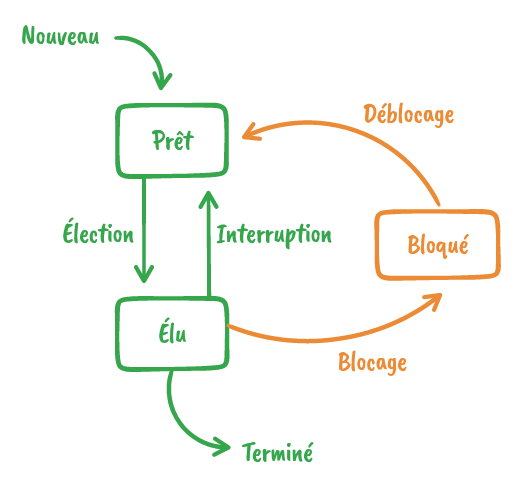
Et de manière simplifiée, voici les différents états...
Ordonnancement des processus
Il est vraiment important de bien comprendre que le « chef d'orchestre » qui attribue aux processus leur état « élu », « bloqué » ou « prêt » est le système d'exploitation. On dit que le système gère l'ordonnancement des processus (tel processus sera prioritaire sur tel autre...)
Important également : un processus qui utilise une ressource R doit la « libérer » une fois qu'il a fini de l'utiliser afin de la rendre disponible pour les autres processus. Pour libérer une ressource, un processus doit obligatoirement être dans un état « élu ».
Simulation : Création d'un processus sous Linux
Au sein des systèmes UNIX, les processus sont identifiés par leur PID (ou Process Identifiant, un identifiant unique) et y sont organisés de façon hiérarchique. Le système d'exploitation utilise un compteur qui est incrémenté de 1 à chaque création de processus, le système utilise ce compteur pour attribuer les PID aux processus.
Un processus peut créer un ou plusieurs processus à l'aide d'une commande système ( « fork » sous les systèmes de type Unix).
Imaginons un processus A qui crée un processus B :
On dira que A est le père de B et que B est le fils de A.
B peut, à son tour, créé un processus C (B sera le père de C et C le fils de B).
On peut modéliser ces relations père/fils par une structure arborescente (voir le cours si nécessaire).
Le PID du fils est renvoyé au processus père pour qu'il puisse dialoguer avec. Chaque fils possède l'identifiant de son père, le PPID (ou Parent Process Identifiant).
Si un processus est créé à partir d'un autre processus, comment est créé le tout premier processus ?
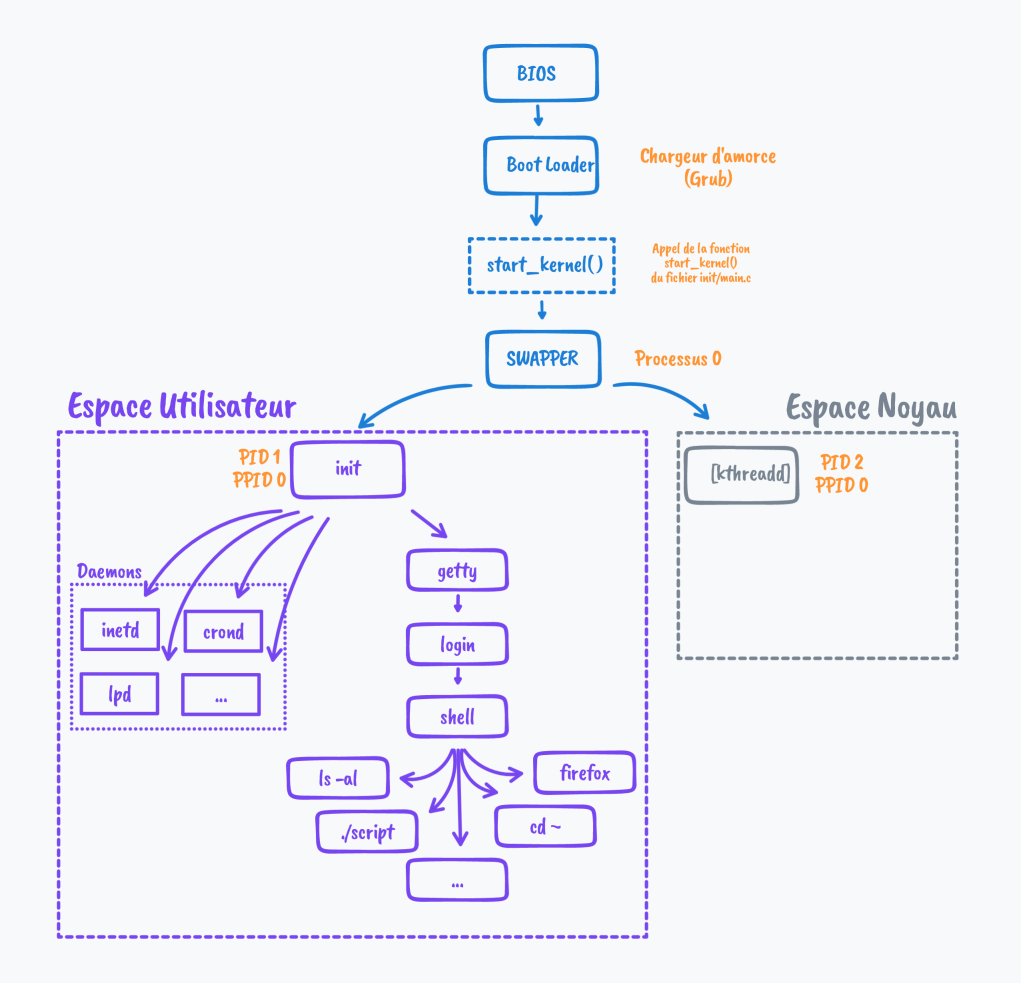
Sous un système d'exploitation comme Linux, suite au démarrage de l'ordinateur un tout premier processus (appelé processus 0 ou encore Swapper) est créé à partir de « rien » (il n'est le fils d'aucun processus). Ensuite, ce processus 0 crée un processus souvent appelé « init » ( « init » est donc le fils du processus 0). À partir de « init », les processus nécessaires au bon fonctionnement du système sont créés (par exemple les processus « crond », « inetd », « getty »,...). Puis d'autres processus sont créés à partir des fils de « init »...
On peut résumer tout cela avec le schéma ci-contre :
Remarque :
Tous ces noms de processus ne sont pas à retenir, ils sont juste donnés pour l'exemple. Il est juste nécessaire d'avoir compris les notions de processus père et processus fils et la structure arborescente.
Attention : Systemd vs Sysv init
Attention, depuis 2015 environ, des changements profonds ont été amorcés sur les distributions Gnu/Linux qui ont adopté systemd (malgré des débats houleux...). Le schéma précédent se base donc sur le programme « init » de Unix System V (SysV init). Toutefois, on retrouve le processus 2 [kthreadd] et le processus 1 qui est pour le coup systemd lancé par la commande /sbin/init (voir les exercices à la suite).
Méthode : Visualisation et gestion des processus
Sous Linux, il existe des commandes permettant de visualiser les processus :
psutilisée avec les optionsaef(ps -aef) permet de visualiser les processus en cours un ordinateur, notamment lesPIDet lesPPIDde ces processus. Problème : La commandepsne permet pas de suivre en temps réel les processus (affichage figé).toppermet d'avoir un suivi en temps réel des processus.killpermet de supprimer un processus. L'utilisation de cette commande est très simple, il suffit de taperkillsuivi du PID du processus à supprimer (exemple :kill 4242permet de supprimer le processus de PID 4242)