Manipuler l'encodage de textes - ASCII et Unicode
Une page HTML d'élève
Vous avez certainement déjà ouvert un courriel ou une page web et observer des caractères étranges comme dans le titre ci-dessus : c'est un problème d'encodage et vous allez reproduire ce problème.
Question
Nous allons écrire une page HTML. Pour cela :
Ouvrir le logiciel Geany et nommer le fichier essai.html.
Dans le menu de Geany, vérifier que l'encodage est bien en UTF-8 (Document > Définir l'encodage > Unicode > UTF-8).
Coller le code HTML suivant dans le fichier :
<html lang="fr">
<head>
<meta charset="utf-8">
<title> accents </title>
</head>
<body>
bébé, élève, où, château.
</body>
</html>
Ouvrir ensuite le fichier avec un navigateur. Vous ne devriez pas avoir de problème de lecture.
Modifier maintenant la ligne <meta charset="utf-8"> en la ligne <meta charset="iso-8859-1"> puis ouvrir le fichier à l'aide d'un navigateur.
Qu'observez-vous lors de cette dernière étape ? Comment l'expliquer ?
Solution
Simulation :
On observe des caractères « bizarres » à la place de nos lettres accentuées.
Pourquoi?
Notre fichier a été encodé lors de l'écriture en UTF-8.
Avec la ligne <meta charset="iso-8859-1">, on dit, par contre, au navigateur de lire le fichier en lui annonçant que ce fichier est encodé suivant la norme iso-8859-1.
Lorsque le navigateur lit le code de la lettre é (codé en utf-8), il cherche la correspondance de ce code, mais il ne cherche pas cette correspondance dans la table de l'utf-8, il la cherche dans la table de iso-8859-1.
Or ce code ne correspond pas en iso-8859-1 à la lettre é. On obtient le caractère (ou les caractères) correspondant au code lu dans la table de l'iso-8859-1.
Remarque :
Vous pouvez bien sûr illustrer le problème dans l'autre sens. C'est à dire choisir d'écrire un fichier HTML en iso-8859-1 (en sélectionnant, dans Geany, à l'ouverture du fichier "Document > Définir l'encodage > Européen de l'ouest > Occidental (iso-8859-1)") puis tenter d'ouvrir ce fichier avec un navigateur avec le charset défini par <meta charset="utf-8">.
Vous obtiendrez de nouveau des caractères bizarres (avec le même texte, vous obtiendrez des caractères bizarres différents de ceux de l'exercice précédent puisque l'interprétation se fait maintenant avec un autre code de départ et un autre décodage à l'arrivée).
Méthode :
En revanche, si vous définissez le même encodage iso-8859-1 sur le fichier crée par Geany et dans le code HTML, alors, cela devrait bien se passer ; faites le test !
Fondamental :
Aujourd'hui, il n'y a plus de questions à se poser : choisissez systématiquement l'encodage UTF-8 !
Question
Dans le cours, on nous dit :
« La table ASCII est codée en UTF-8 de U+0000 à U+007F »
Justifier que l'ensemble de la table ASCII 'rentre' dans cet espace alloué ?
Indice
Ce sont des caractères hexadécimaux.
Question
Malheureusement, le site ci-dessous a été corrigé :( Si vous en trouvez un nouveau, merci de le signaler. Cependant, que pouvez-vous suggérer au développeur du site ?
Aller sur ce site internet : http://www.lyonlocation.fr/
Que constatez-vous ?
Après avoir enregistré la page HTML sur votre ordinateur, proposer une modification dans le fichier
Validez votre correction avec un aperçu dans Mozilla Firefox.
Exercices avec Python
Attention ! Tous les exercices ci-dessous ne sont pas corrigés, vous prendrez soin de conserver vos codes (ou de les noter dans votre cahier) afin de les retrouver plus tard.
Pour ces exercices, on se rappellera des « techniques » pour parcourir une chaîne de caractères. Le parcours de listes se fait de la même manière...
Question
Écrire un script Python qui affiche les lettres de l'alphabet en minuscules puis en majuscules avec leur code ASCII associé.
Pour vous faire gagner du temps, on vous donner cela :
lettres = 'abcdefghijklmnopqrstuvwxyz'
Indice
On utilisera une fonction Python vue précédemment.
Indice
Une méthode bien utile en Python : upper(), à utiliser...
Question
Écrire un script Python qui affiche les 256 caractères de la table ASCII étendue. De quel type sont ces caractères ?
Indice
On utilisera une fonction Python vue précédemment.
Indice
On remarquera que certains caractères bloquent l'affichage des caractères jusqu'au 256 caractères, excluez-les de votre boucle for.
Question
Fonction de décodage...
Soit la liste suivante :
[233, 112, 97, 116, 97, 110, 116, 32, 33]
correspond à la liste des codes Unicode d'une chaîne. Laquelle?
Vous écrirez une fonction python de "décodage".
Indice
>>> chr(128690)
'🚲'Lecture de quelques caractères sous forme d'octets
Un éditeur hexadécimal est un logiciel permettant de visualiser et éditer le contenu de fichiers, en visualisant leurs données en octets (présentés sous forme de caractères hexadécimaux).
Nous utilisons ci-dessous un éditeur hexadécimal (GHex sur Gnu/Linux) sur un simple fichier texte (.txt) : on observera donc directement les octets associés au caractère au lieu du caractère. Tandis qu'avec un éditeur de texte, comme Geany, c'est bien le texte qui sera lu.
En bref, on peut considérer que l'éditeur de texte (ou un lecteur d'image s'il s'agit d'un fichier image, ou un lecteur de musique, etc...) tient compte des métadonnées[1] pour savoir comment interpréter le code, tandis que l'éditeur hexadécimal ne tiendra pas compte des métadonnées : il ne cherche pas à interpréter le code, il l'affiche.
Question
Exercice 1 : lecture d'un simple fichier texte
Créer un fichier
a.txtdans lequel vous entrez simplement la lettre a.Ouvrir avec le logiciel GHex, présent sur les ordinateurs, ce fichier texte.
Qu'observez-vous ?
Comment interprétez-vous le code affiché ?
Indice
Vérifiez ce que vous voyez avec les fonctions Python précédemment vues.
hex() permet de trouver le code hexadécimal.
Solution
Pas de solution, mais notez bien ce que vous constatez.
Question
Exercice 2
Recommencer le travail mais avec la lettre é.
Avec un premier fichier encodé en utf8.
Avec un second fichier encodé en iso-8859-1.
Solution
Fichier encodé en utf8
Ce qui a été vu précédemment ne semble plus correspondre...
C'est normal ! Il ne faut pas confondre Unicode qui identifie des caractères par des nombres et l'encodage utf8 qui va associer à (la plupart) des caractères Unicode une suite d'octets. D'autres encodages des caractères Unicode comme utf16 par exemple donneront en général une autre suite d'octets.
Par contre, il y a bien coïncidence pour les caractères de la table ASCII (utf-8 étant défini pour préserver cela).
'é'.encode('utf8')
donnera
b'\xc3\xa9'Complément :
Pour faire le point entre Unicode et UTF-8, voici 2 ressources intéressantes à lire :
Différence entre Unicode et UTF-8 : https://fr.esdifferent.com/difference-between-unicode-and-utf-8
un historique...
Solution
Fichier encodé en iso-8859-1
Ne pas oublier de le faire :)
Exercice 3 : question existentielle...
Pourquoi le caractère é en UTF-8 devient-il é en ISO 8859-15 ?

Question
Question 1 :
Grâce à la fonction ord() puis à la fonction bin(), écrire en binaire le nombre associé au caractère é en UTF-8.
Solution
>>> ord('é')
233>>> bin(233)
'0b11101001'Donc en UTF-8, é est associé au nombre 11101001.
Question
Question 2 :
D'après l'explication de fonctionnement de l'encodage adaptatif de l'UTF-8[3] (voir le tableau dans le cours), les 8 bits nécessaires à l'encodage de é en UTF-8 vont être «encapsulés» dans 2 octets de la forme 110XXXXX 10XXXXXX, où les 11 X représentent les 11 bits d'information disponibles.
Écrire ces 2 octets en complétant si nécessaire avec des 0 à gauche.
Solution
Sur 11 bits, le nombre 11101001 va s'écrire 00011101001.
En séparant ces 11 bits en deux groupes de 5 bits et 6 bits (00011et 101001), et en les encapsulant, on obtient les deux octets 11000011 10101001.
Question
Question
Question 4 :
Si un logiciel considère à tort que les deux octets servant à encoder le é en UTF-8 servent à encoder deux caractères en ISO 8859-15, quels seront ces deux caractères ?
On vous fourni pour cela la table ISO 8859-15 :
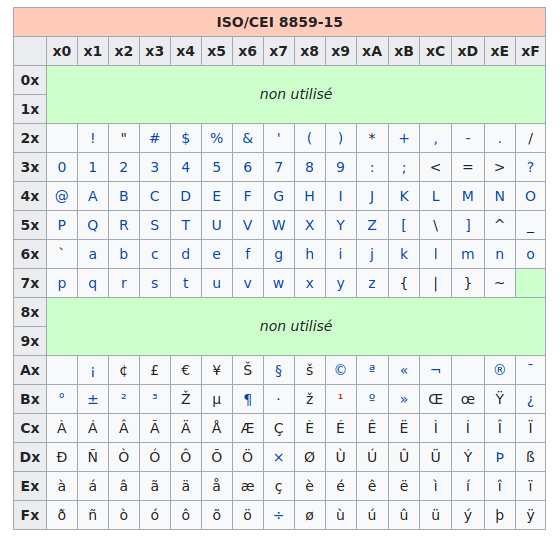
Indice
Dans la table, le premier chiffre est à choisir parmi les lignes, et ensuite, parmi les colonnes.
Exemple ù est encodé en f9.
Solution
Grâce à la table d'encodage ISO 8859-15 ci-dessus, on s'aperçoit que :
Le premier octet,
c3en hexadécimal, sera perçu en ISO 8859-15 comme le caractèreÃ.
Le deuxième octet,
a9en hexadécimal, sera perçu en ISO 8859-15 comme la lettre©.
Finalement, ce qui aurait dû être un é en UTF-8 se retrouvera être un é en ISO 8859-15.