Algorithmes de routage dynamique
Il est impossible au niveau d'Internet ou même de gros réseaux d'entreprises de définir statiquement les tables de routages de milliers voire de milliards de machines. Des algorithmes pour automatiser cette tâche sont utilisés.
]")
Routage et taille des réseaux
Les protocoles de routage dépendent de la taille du réseau.Nous n'étudierons que les réseaux de petite ou moyenne taille.
On remarque dans l'image ci-dessus la notion de systèmes autonomes (autonomous systems, AS) ; Internet est composé de ce type de systèmes qui ne cessent de grossir :
36 000 en 2011
96 000 en 2020 avec une forte disparité selon les continents 27 629 aux USA et 4 en Mauritanie par exemple.
Un système autonome est un ensemble de réseaux informatiques IP intégrés à Internet et dont la politique de routage interne (routes à choisir en priorité, filtrage des annonces) est cohérente, généralement sous le contrôle d'une entité ou organisation unique, typiquement un fournisseur d'accès à Internet (Orange, Free...) ou une très grande entreprise du numérique, les GAFAM par exemple.
Les routeurs mettent à jour leurs tables en fonction des tables des routeurs voisins. Il existe 2 grands groupes d'algorithmes au programme de Terminale parmi les routeurs appartenant à un même système autonome :
Algorithme à vecteur de distances RIP (Routing Information Protocol), basé sur l'algorithme de détermination des routes décentralisé Belleman-Ford
Algorithme à état de liaison OSPF (Open Shortest Path First), basé sur l'algorithme de Dijkstra.
Fondamental : Algorithme à vecteur de distances RIP
C'est historiquement le premier algorithme de routage. L'idée est que chaque routeur associe à chaque destination possible la plus courte distance en sauts (hops), c'est à dire en nombre de routeurs traversés pour aller au réseau demandé.
Déroulé de l'algorithme :
Chaque routeur a, dans sa table, les réseaux directement accessibles sans passer par un autre routeur (donc à une distance de 0)
Périodiquement, toutes les 30s, chaque machine écoute les annonces des passerelles (gateways qui permettent de sortir du réseau local) publiant leurs tables : elle met ainsi à jour ses propres tables si des chemins plus courts ou de nouvelles destinations apparaissent. Les distances sont mises à jour ainsi que le nom du premier routeur qu'il faut joindre pour accéder au réseau : distance + direction = vecteur.
Si un réseau n’apparaît plus dans les annonces, au bout d'un certain temps (3 mn), il est supprimé des tables.
Les 3 caractéristiques principales qui distinguent l'algorithme RIP de OSPF sont :
la distance est mesurée en nombre de sauts et ne tient pas compte de la bande passante de chaque liaison ;
chaque routeur n'a d'information que sur ses voisins donc n'a pas de vision globale du réseau (on parle de routing by rumor) ;
il y a une distance maximale permise de 15 sauts (16 représente l'infini) et les tables ont 25 entrées au maximum.
Ainsi, cet algorithme ne peut s'appliquer qu'à de petits réseaux et est sensible à certaines attaques...
Complément : En savoir plus...
Fondamental : Algorithme à état de liaison OSPF
OSPF a été implémenté pour palier aux faiblesses de RIP énoncées au dessus. Son fonctionnement est donc plus efficace mais aussi plus complexe.
Voici les grands principes :
les routeurs ont une vision globale du réseau car ils reçoivent des informations de tout le réseau (mais de manière intelligente et efficace). Tous les routeurs ont donc une connaissance identique du réseau.
les distances sont mesurées de manière plus fine : on tient compte du nombre de sauts mais aussi du débit de chaque liaison reliant 2 routeurs par exemple, en général, c'est le rapport entre une bande passante de référence et celle du câble exprimées dans la même unité. Les débits binaires sont souvent données en kbps ou kb/s (kilobits par seconde) ou MB/s (megabit par seconde).
Chaque réseau peut-être schématisé par un graphe. Ainsi donc, les routeurs et les switches sont les sommets, leurs liaisons sont les arêtes, les étiquettes des arêtes sont les coûts. Si on reprend le réseau de la page suivante, on peut le représenter ainsi :
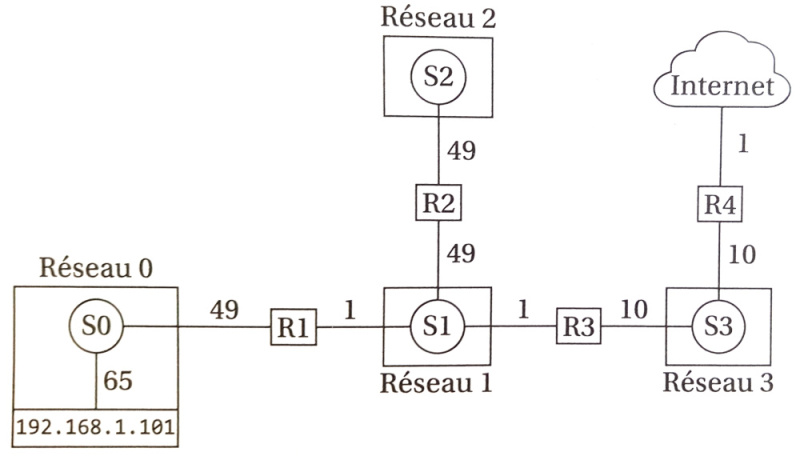
On peut appliquer l'algorithme de Dijkstra (voir ci-dessous) pour obtenir les routes les moins coûteuses et sans cycle. Chaque routeur devient alors la racine d'un arbre qui contient les meilleurs routes.
Complément : En savoir plus...
Wikipédia : https://fr.wikipedia.org/wiki/Open_Shortest_Path_First
Algorithme de Dijkstra expliqué simplement par Yvan Monka :